Stop Catalogue, Pricing, and Content Scraping
Trace extraction attempts from product, price, search, listing, and article routes, then connect scraper signals to the right edge action before the traffic drains origin capacity or copies proprietary data.

Scrapers Move Through High-Value Data Paths
Scraping does not look like one generic bot visit. It often starts with repeated catalogue, pricing, search, listing, API, or article requests, then scales through automation until competitors, aggregators, or AI pipelines have copied the data your business depends on.
Catalogue and Listing Harvesting
Bots enumerate product, inventory, directory, and search pages so they can rebuild your structured data outside your control.
Pricing and Availability Extraction
Repeated price, inventory, and promotion checks expose competitive signals during sales, ad campaigns, and repricing windows.
Content and Model Training Assets
Article, review, media, and specification pages can be copied into unauthorised content products or AI training and retrieval workflows.


Turn Scraper Signals Into Edge Decisions
Peakhour evaluates the request trail behind extraction: automation signatures, proxy use, device and browser signals, route mix, request cadence, and session history. The result is a policy decision that fits the risk instead of a blanket block on every visitor.
-
Scraper Signal Correlation
Connect repeated route access, bot fingerprints, headless or scripted behaviour, and suspicious user-agent patterns into one risk picture.
-
Proxy and Cadence Detection
Identify residential proxy rotation, datacentre bursts, low-human browsing cadence, and distributed request patterns that hide extraction volume.
-
Targeted Response
Allow trusted shoppers and readers, challenge uncertain sessions, rate-limit noisy collectors, or block confirmed scraper signatures before they reach origin.
The Decision Trail Stays Attached to the Scraping Flow
The visual roadmap shows the flow; decision records support the operational review. Teams can see which routes were targeted, which scraper signals contributed to the score, and whether Peakhour allowed, challenged, limited, or blocked the session.
The decision trail supports review while the page narrative stays focused on the scraping flow and protected data path.
What Peakhour Protects in the Scraping Flow
Route-Aware Bot Management
Treat catalogue, price, API, search, listing, and content routes as distinct risk surfaces with a decision record attached to each action.
Cadence-Based Rate Limiting
Slow repeated collectors that request too quickly, enumerate too broadly, or shift identities while following the same extraction path.
Low-Friction Challenges
Challenge uncertain sessions when the signals are suspicious but not strong enough for a hard block.
WAAP and Origin Protection
Keep abusive automation away from protected application routes, APIs, and origin infrastructure.
Residential Proxy Detection
Expose proxy-backed scraping that rotates IPs while preserving the same target routes and machine-like request timing.
Related evidence
Scraping Pressure Reduced in Production
Customer examples that connect Peakhour controls to production outcomes.

Gumtree
Improving Traffic Quality and Reclaiming Platform Control
Gumtree, Australia's leading marketplace, battled significant bot traffic that skewed analytics, enabled scammers, and increased infrastructure costs. Peakhour's bot management solution improved the origin traffic mix, cleaned up campaign analytics, protected A/B testing data, and created a new revenue stream.

Kitchen Warehouse
COVID-19 Traffic Surge Success
How Australia's #1 online kitchenware retailer thrived during COVID-19's unprecedented traffic surge and achieved 150% revenue growth with Peakhour's performance solutions.
Connect Scraping Protection to Traffic Quality
Bot Management
Score scraper behaviour with fingerprint, proxy, request, and session signals.
Advanced Rate Limiting
Slow extraction cadence before collectors overload routes or origin infrastructure.
Application Security Platform
Protect application and API routes that expose valuable content, pricing, and account data.
Protect Ad Spend
Use traffic-quality signals when scraping and bot traffic also pollute paid media and conversion data.
API Bot Protection
Extend scraper controls to product, pricing, account, and checkout APIs that expose high-value data.
Keep Scraped Data and Scraper Load Away from Origin

Learn More About Scraper and Bot Decisions

Layer 7 DoS attacks and Full Page Caching
Discover how Full Page Caching can help mitigate layer 7 DoS attacks.
Read More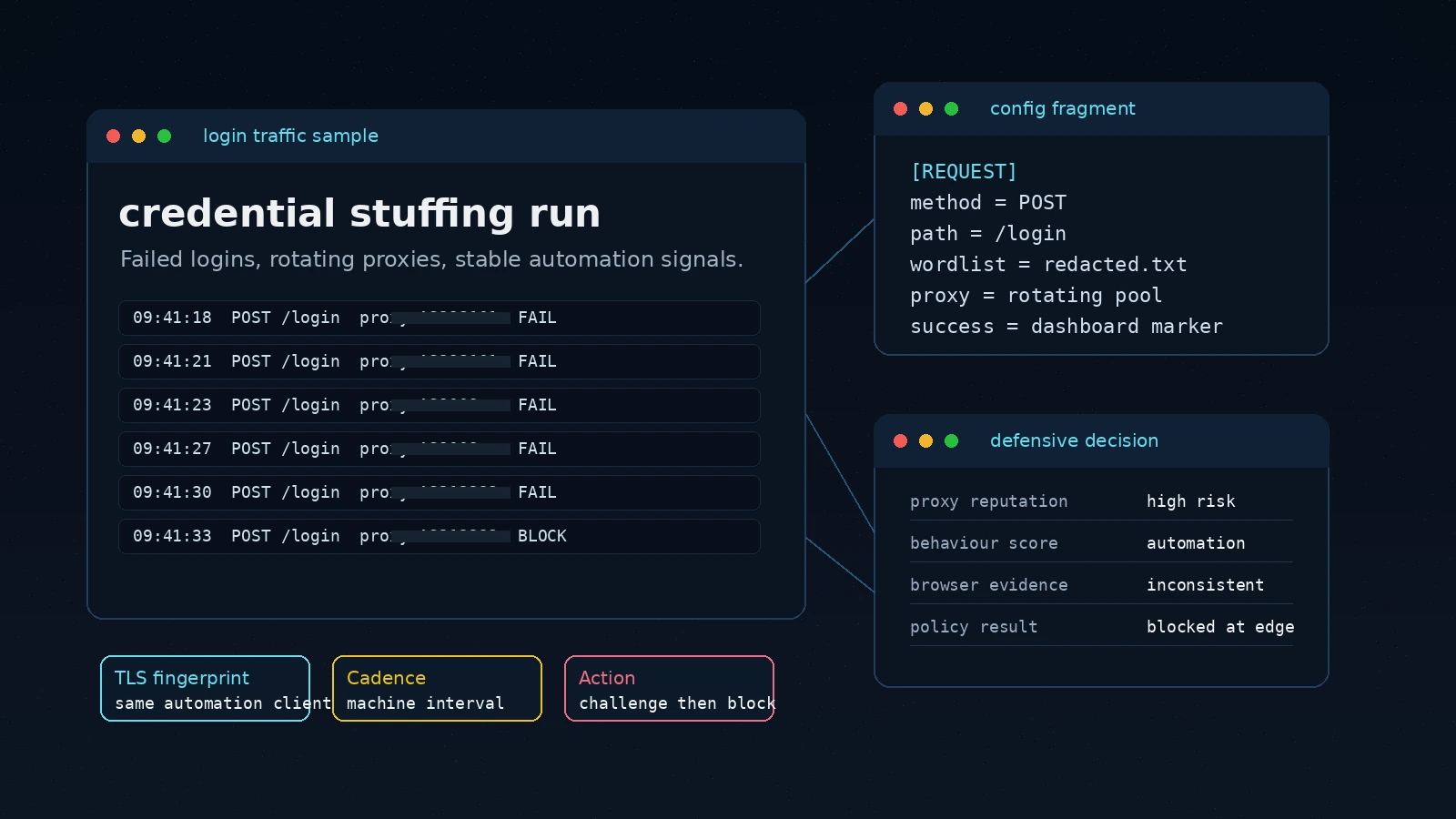
The Rise of OpenBullet: Automation Tool or Cybersecurity Threat?
A comprehensive look at OpenBullet, its capabilities, and the implications for cybersecurity in the face of its misuse.
Read More
Residential Proxies, Friend or Foe?
This article explores the world of residential proxies, revealing the challenges and ethical questions they pose in our GeoIP-dependent digital landscape.
Read More
Price transparency needs governed automation
Price comparison increasingly depends on current web and API data. See how governed automation separates intended access from abusive extraction.
Read More